

How Power Platform scales generative AI across an organization
The below has been excerpted and adapted from my recent white paper, Crafting your Future-Ready Enterprise AI Strategy, published with Microsoft in January 2024. There’s much more in the paper, so give it a download, pour yourself a drink, and enjoy the read.
I am as fascinated by how many generative AI, data platform, and other Azure Cloud practitioners I find who don’t appreciate the capability of Power Platform to scale their cloud as I am surprised by how many Power Platform practitioners don’t seem to grasp where the true power of the platform lies. Truth is that generative AI, a proper data platform, and Power Platform desperately need one another. In other words:
Power Platform scales AI and the data platform by (a) providing a composable means of both data collection and delivery of insights and AI capability back to the user;
The great, often unsung capability of Power Platform is not the “app”, rather the ability (via Dataverse) of data transacted in a Power Platform solution to hydrate downstream data distribution scenarios such as analytical workloads, enterprise search, and—you guessed it—whatever AI infused workload you dream up.
Let’s explore this.
Fast forward through the first twenty-seven pages of the white paper and we come to the notion that great discipline is required to maintain a healthy data platform over time, for example by avoiding the temptation to revert to the legacy pattern of siloed, inconsistent, data services or point-to-point integration. That is to architect individual applications such that they don’t run off and spawn a new generation of one-off data siloes just as you’ve exorcised the data demons of your past, maintaining the index across your estate, etc. Microsoft’s Power Platform can help immensely.
Forrester’s 2022 study, The Total Economic Impact of Microsoft Power Platform Premium Capabilities, found 63% of IT decision makers reporting that Power Platform helped them eliminate or rein in shadow IT, which is good news for an AI-powered future where data consolidation, governance, security, etc. is paramount. I wrote at length about the Forrester study in my early 2023 piece here, so give that a look if you want to go a bit deeper on it.
In fact, it is impossible to scale AI across your cloud ecosystem absent of Power Platform integration for three reasons:
Properly executed Power Platform allows traditional software and data engineers to build workloads faster, whilst simultaneously allowing non-technical “citizen developers” to self-service many of their own productivity needs in a safe, secure way (thereby freeing professional engineering time to focus on more complex workloads).
Every organization I have ever encountered has vast swathes of its data estate buried in the types of productivity solutions (e.g., spreadsheets, Access databases, small third-party “shadow IT” solutions) that are not addressable by AI because they are not consolidated. As such, it is cost and time prohibitive to bring this data out of the shadows and to address the tier one and tier two workloads with professional engineering talent alone.
Microsoft is building AI capabilities into Power Platform itself, essentially making Power Platform as indispensable an ingredient to your AI strategy as Azure AI Search and Azure AI services themselves. For example:
Copilot Studio, Microsoft’s service for organizations building their own custom “Copilots” is built atop what was previously known as “Power Virtual Agents,” which is architecturally ingrained with Power Platform. In other words, we now build custom Copilots in Power Platform itself.
Power Platform includes AI capabilities that developers can embed in their solutions, allowing users to, for example, chat with the app and have AI-driven insights returned to them using data in the application itself.
Investing in and standardizing on Microsoft Dataverse (the principle data service underlying Power Platform solutions) as your first port of call for transactional application data offers a repeatable pattern where apps are built atop a data service that in one hop consolidates data into a data lake generally or Microsoft OneLake specifically. This pattern is readily applicable to tier one or critical core business systems as well as to tier two and three (or below)—more productivity centric—applications.
Let’s consider an applied example of this.
The diagram below shows a series of workloads (red icons) each representing an “app,” or a series of apps, placed in the hands of various users in a typical globally-distributed organization. These workloads use Microsoft Dataverse as their “single source of truth” for transactional application data.
This “functional ecosystem map” shows different workloads (red icons) that might typically be found in a globally-distributed enterprise organization. The map is illustrative, though it’s highly likely that most organizations will see something of their own needs here.
Try to take this in without getting hung up on the specifics of each workload. This diagram depicts a generic organization that could be found in nearly any industry. It’s really a composite of workloads that I have personally been involved with implementing in sectors diverse as financial services, professional services such as big law firms, manufacturing, retail and distribution, emergency services (e.g., law enforcement, medical, rescue, coast guard, etc.), the military, and other public sector and non-governmental organizations that deploy or maintain personnel globally. Long-time readers of this blog may have seen a version of this diagram before.
For example, the “Medical” workload may not be relevant to an insurance firm, but is certainly relevant to a law enforcement agency, the military, or even an industrial firm where safe operation of heavy equipment is a concern. We could have easily substituted that “Medical” workload in favor of an “Underwriter Workbench” workload for that insurance firm.
Everything I'm sharing here has been built in the real world, and don't get too hung up on the details.
Now let’s reshuffle those workloads a bit and combine them with the AI architecture and “retrieval augmented generation” (RAG) discussed in my recent piece, “RAG and the fundamentals of AI acting on enterprise data”. Notice that the link through which Dataverse pushes its data into OneLake glows in blue to highlight the “one hop” nature of that link. OneLake includes a native “shortcut” connector that allows it to treat Dataverse data as if it were resident in the lake without having to copy the data into the lake.
Functional workloads (red icons) from our previous diagram have been arranged with Dataverse and combined with our previous AI architecture to demonstrate how this data may flow to AI workloads.
Let’s finally highlight (glowing in blue) all of the components in this architecture that can be built with Power Platform.
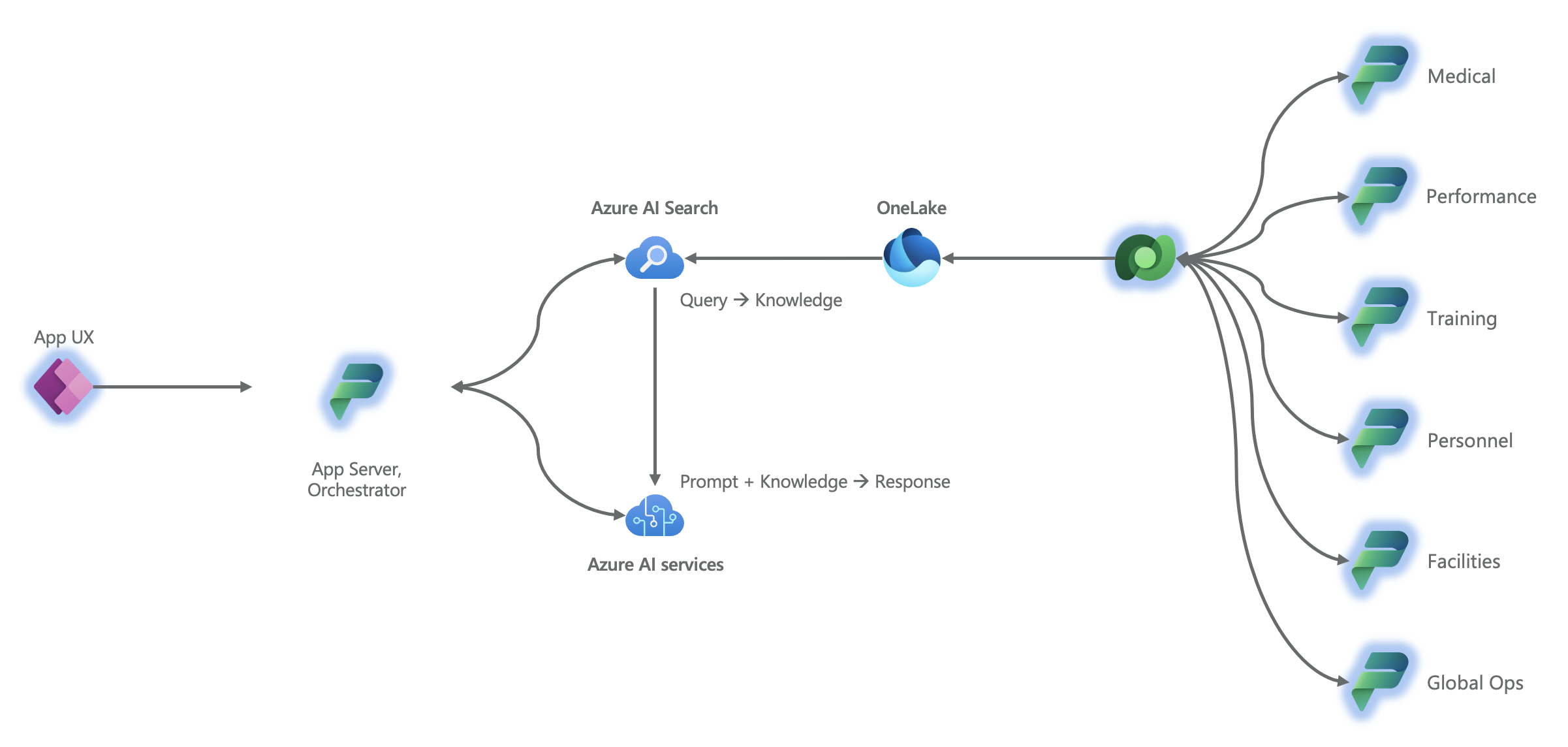
The previous diagram, but with function-specific icons replaced with Power Platform icons (glowing in blue) to demonstrate how Power Platform combined with Azure data services and Azure AI services supports scaling AI across the organization.
As you can see, Power Platform operating alongside Azure AI services and Azure data services (Microsoft Fabric) makes for a compelling combination. Modernizing both tier 1/2 and productivity “shadow” apps to Power Platform provides outsize value in scaling AI across the organization in addition to the many other benefits of this app modernization approach (which are other stories for other times).
I invite you to explore more of this and related topics in the Crafting your Future-Ready Enterprise AI Strategy white paper.